Architecture
Retrieval augmented generation (RAG) is a powerful technique for adding context to your LLM responses. However, the retrieval step involves API calls and therefore you usually need to iterate on RAG applications in your codebase. Braintrust offers an alternative workflow, where instead, youpush the retrieval tool from your codebase to Braintrust. Using Braintrust functions, a RAG agent can be defined as just two components:
- A system prompt containing instructions for how to retrieve content and synthesize answers
- A vector search tool, implemented in TypeScript, which embeds a query, searches for relevant documents, and returns them
Getting started
To get started, you’ll need a few accounts: andnode, npm, and typescript installed locally. If you’d like to follow along in code,
the tool-rag
project contains a working example with all of the documents and code snippets we’ll use.
Clone the repo
To start, clone the repo and install the dependencies:.env.local file with your API keys:
OPENAI_API_KEY environment variable in the AI providers section
of your account, and set the PINECONE_API_KEY environment variable in the Environment variables section.
We’ll use the local environment variables to embed and upload the vectors, and
the Braintrust variables to run the RAG tool and LLM calls remotely.
Upload the vectors
To upload the vectors, run theupload-vectors.ts script:
docs-sample directory, breaks them into sections based on headings, and creates vector embeddings for each section using OpenAI’s API. It then stores those embeddings along with the section’s title and content in Pinecone.
That’s it for setup! Now let’s try to retrieve the vectors using Braintrust.
Creating a RAG tool
Braintrust makes it easy to create tools and then run them in the UI, API, and, of course, via prompts. This is an easy way to iterate on assistant-style agents. The retrieval tool is defined inretrieval.ts:
Try out the tool
To try out the tool, visit the project in Braintrust, and navigate to Tools.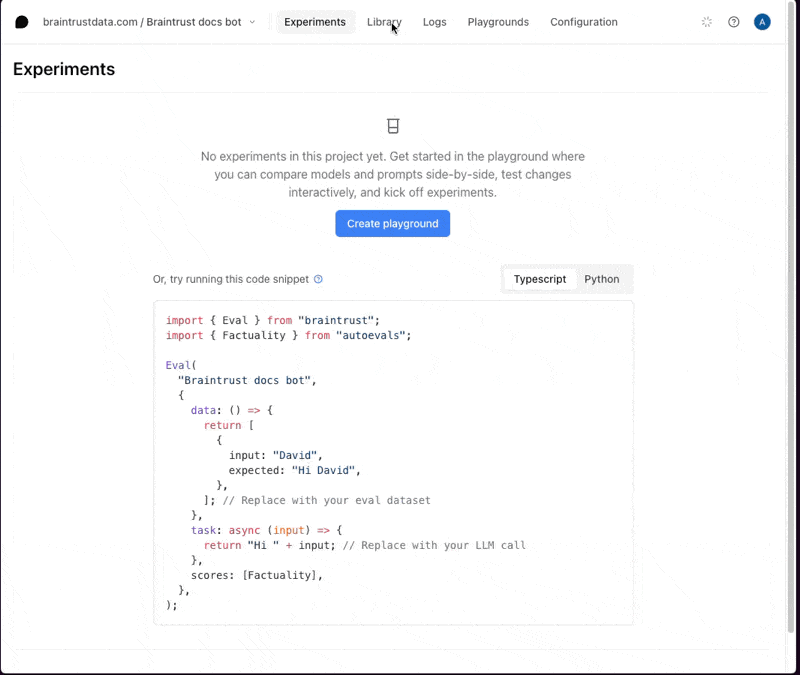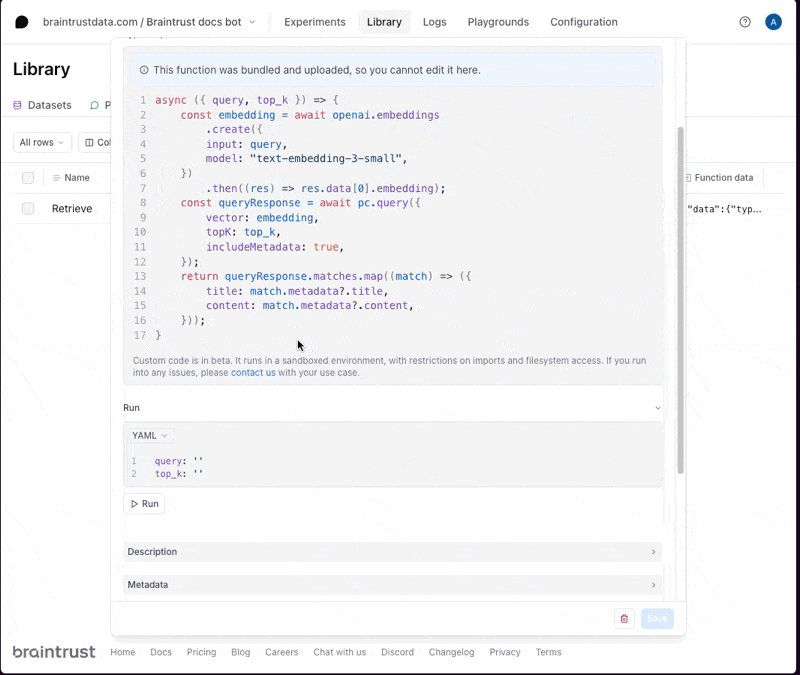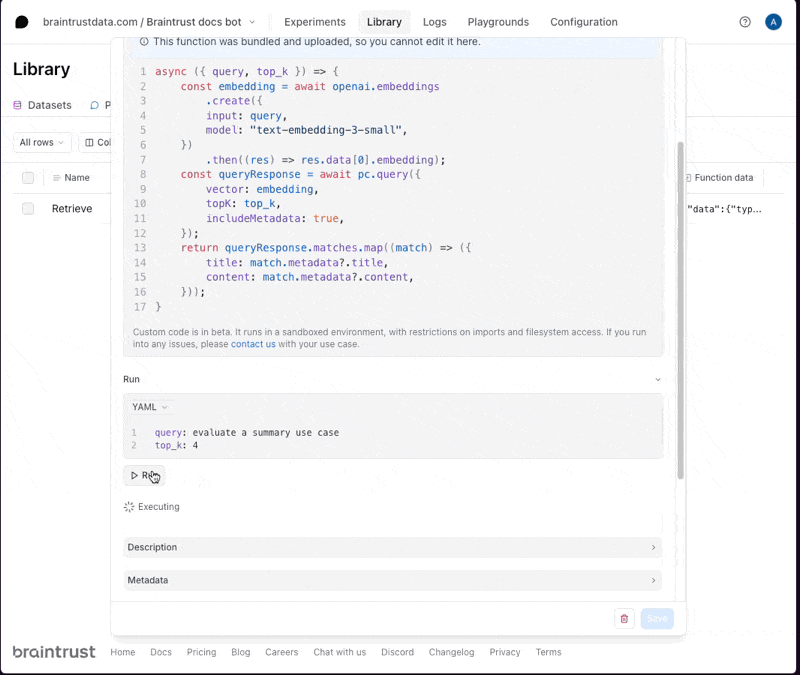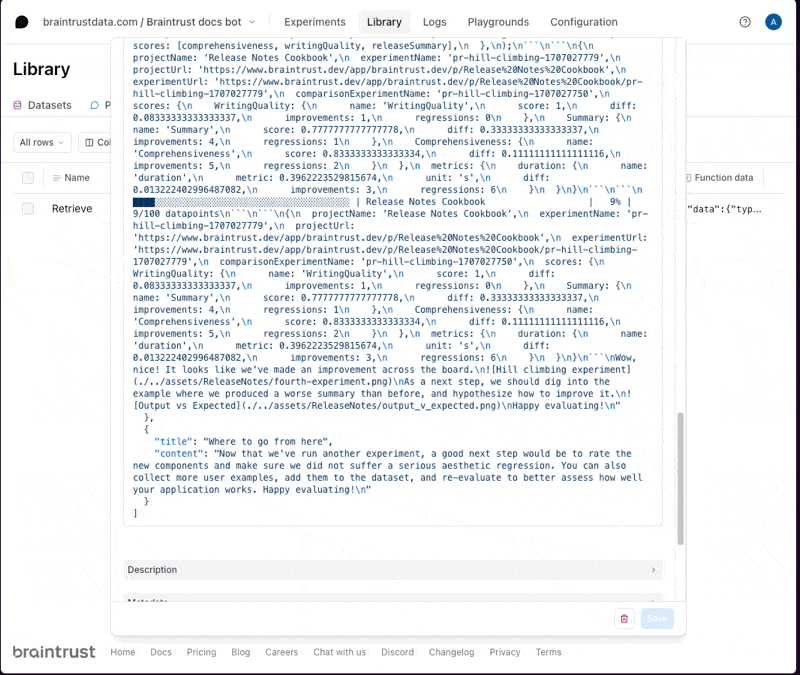
top_k values, or adding a prefix to the query to guide the results. If you change the code, run
npx braintrust push retrieval.ts again to update the tool.
Writing a prompt
Next, let’s wire the tool into a prompt. Inprompt.ts, there’s an initial definition of the prompt:
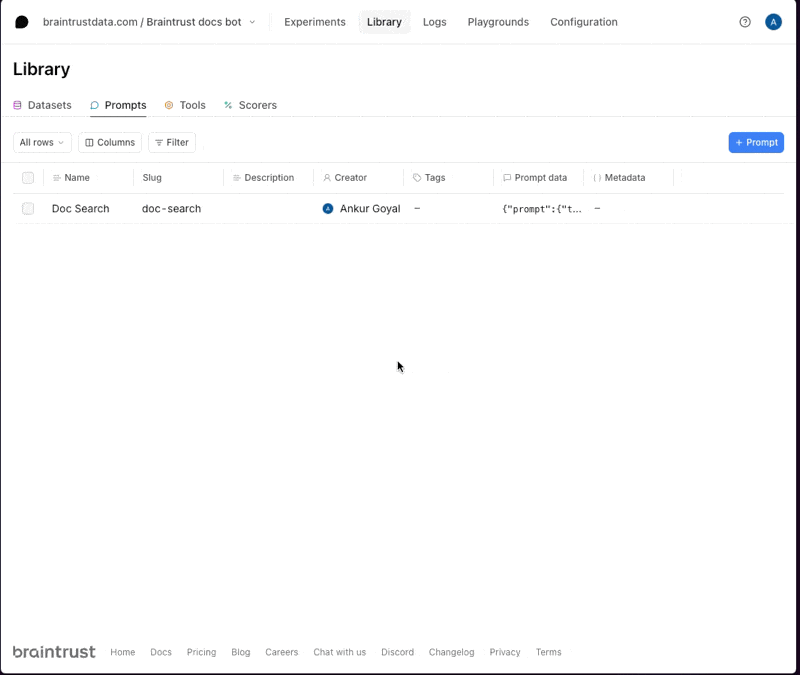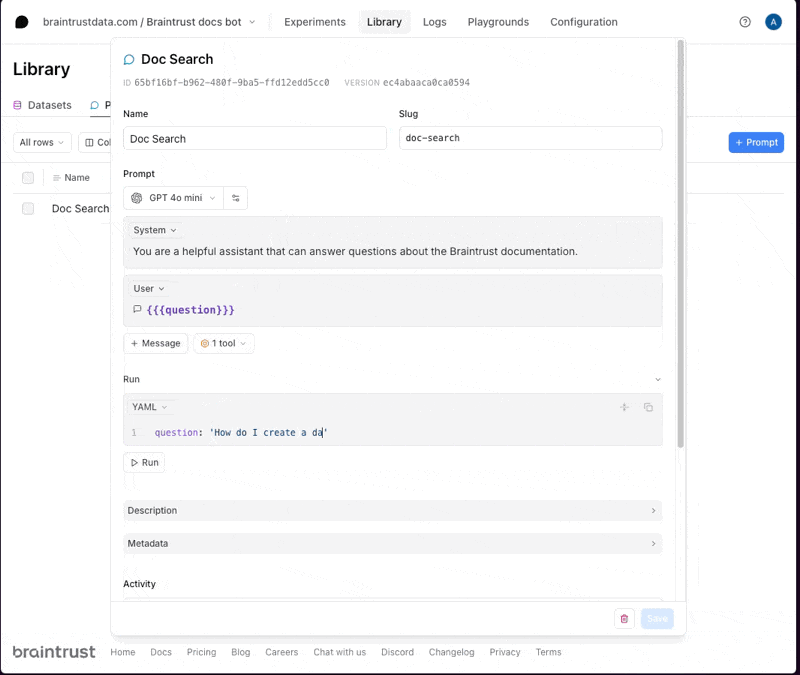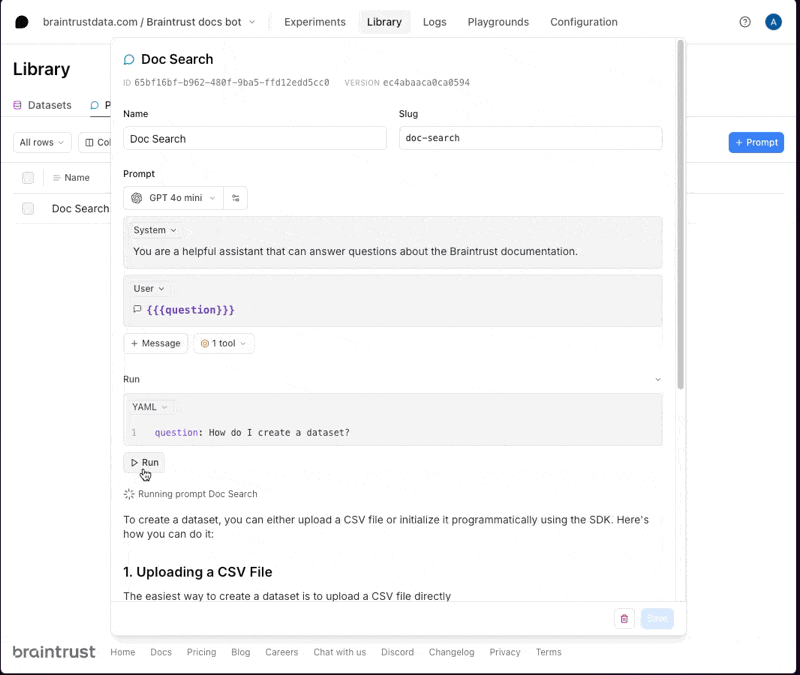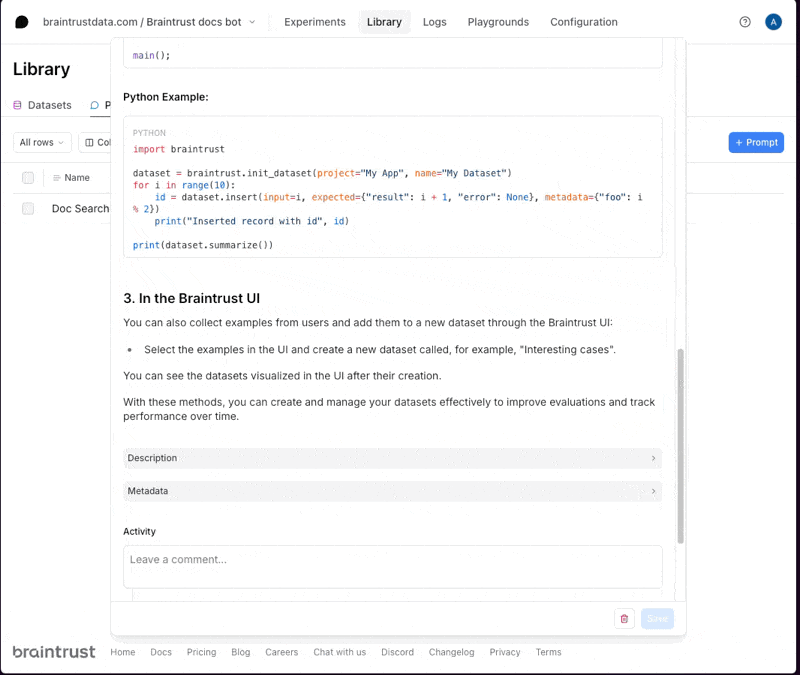

We recommend using code-based prompts to initialize projects, but we’ll show
how convenient it is to tweak your prompts in the UI in a moment.
Import a dataset
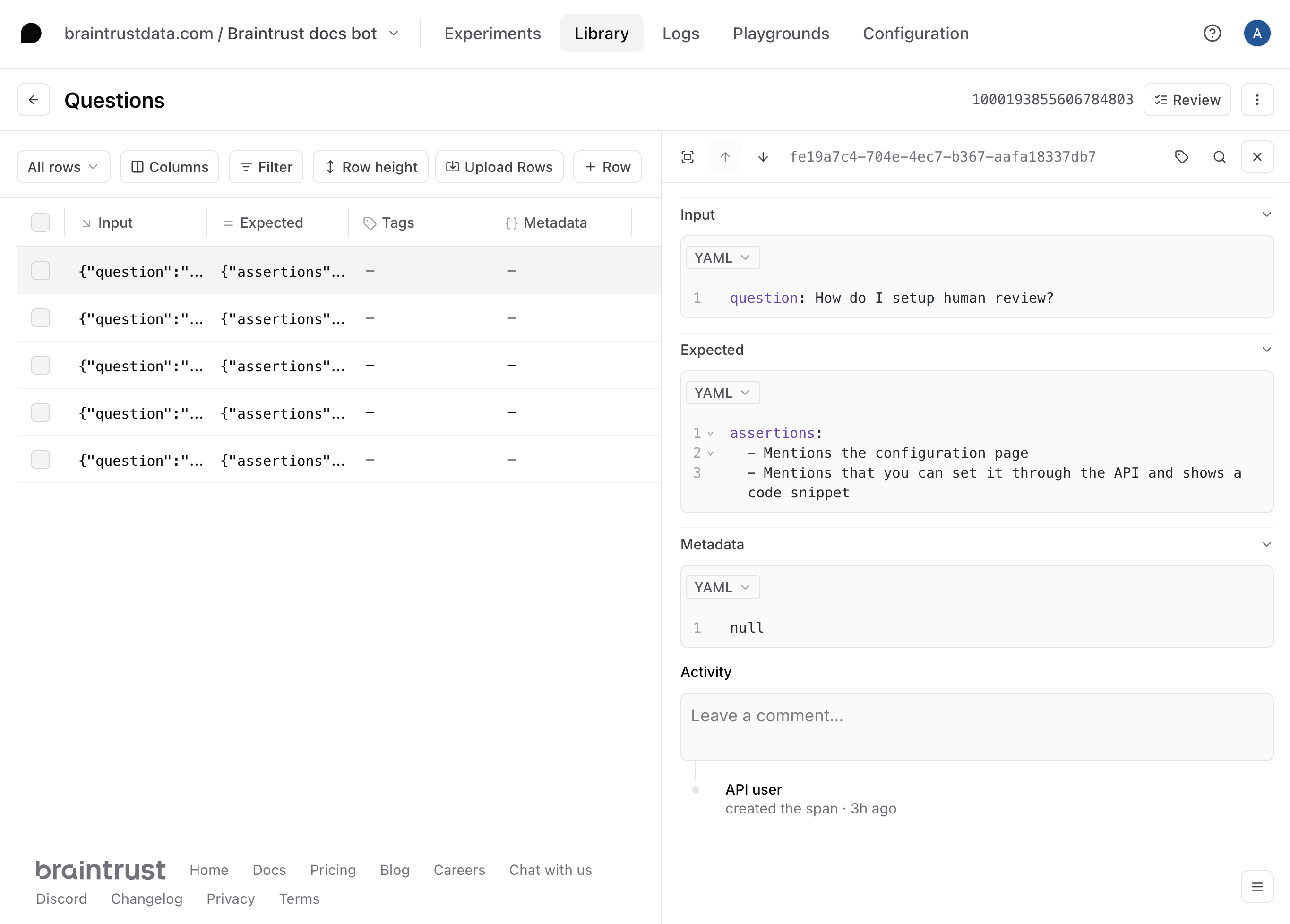
To get a better sense of how well this prompt and tool work, let’s upload a dataset with a few questions and assertions. The assertions allow us to test specific characteristics about the answers, without spelling out the exact answer itself. The dataset is defined inquestions-dataset.ts, and you can upload it by running:
Create a playground
To try out the prompt together with the dataset, we’ll create a playground.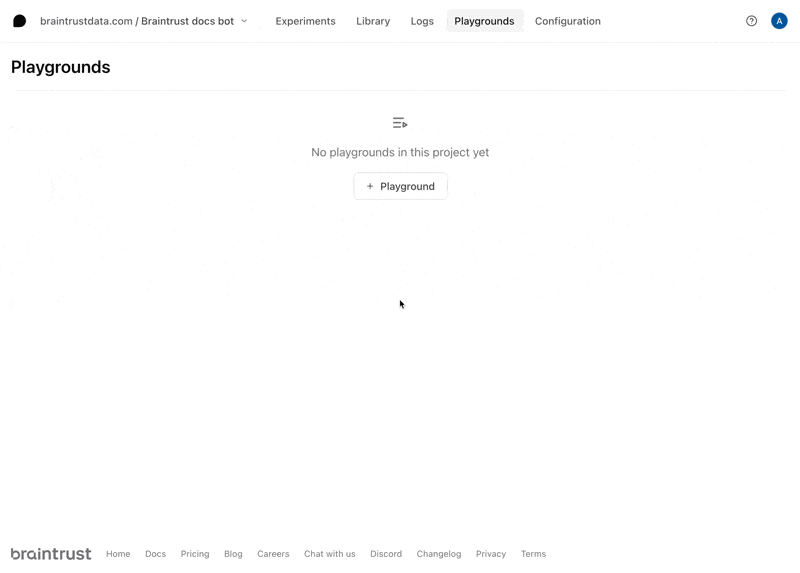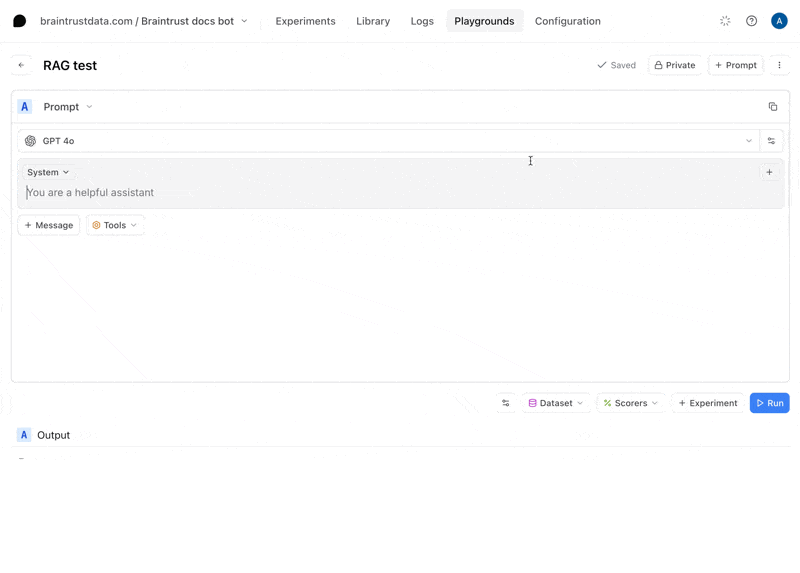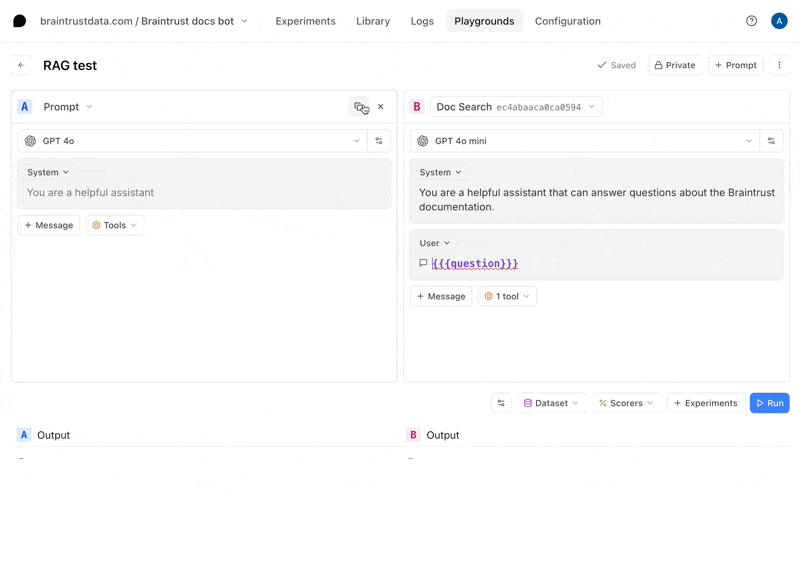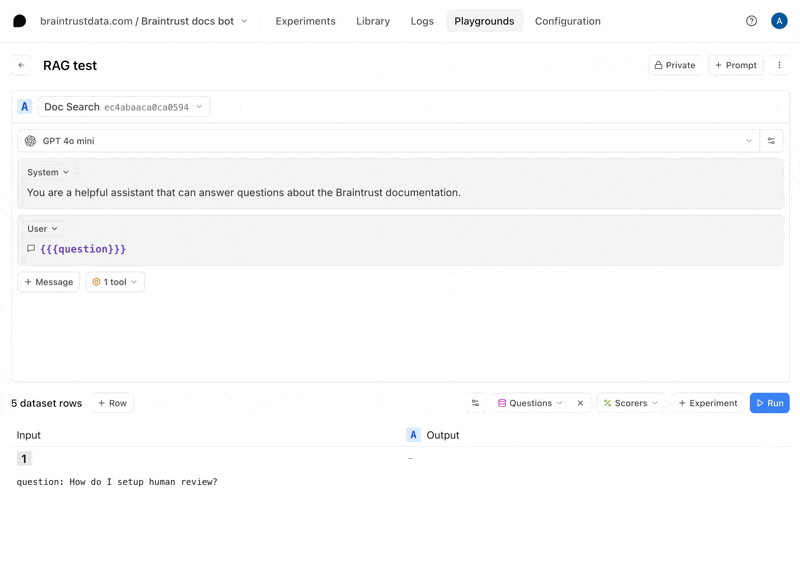
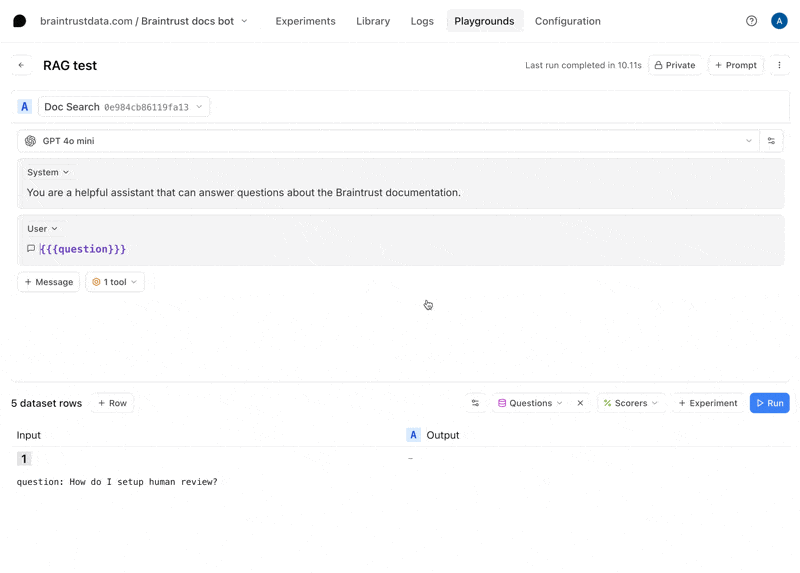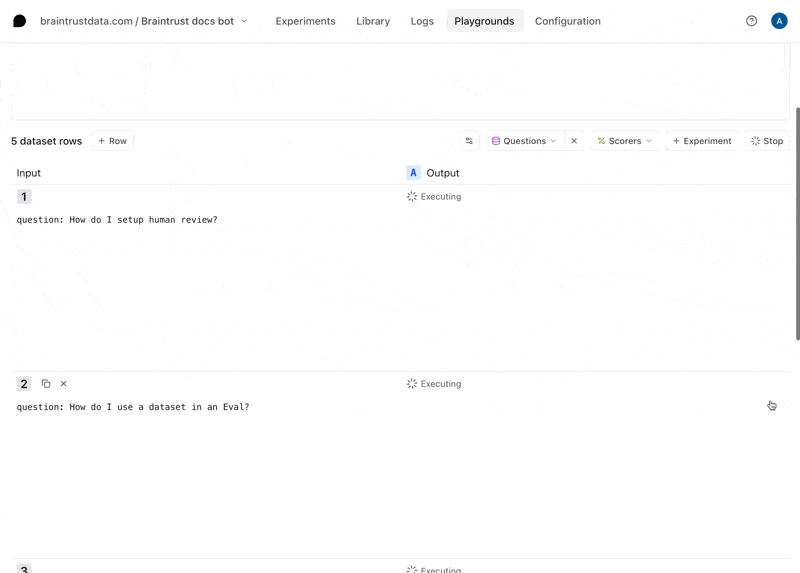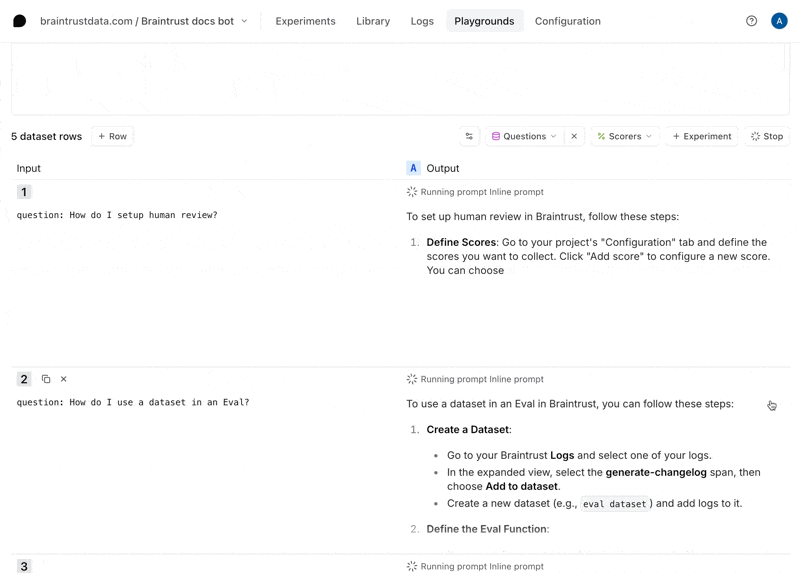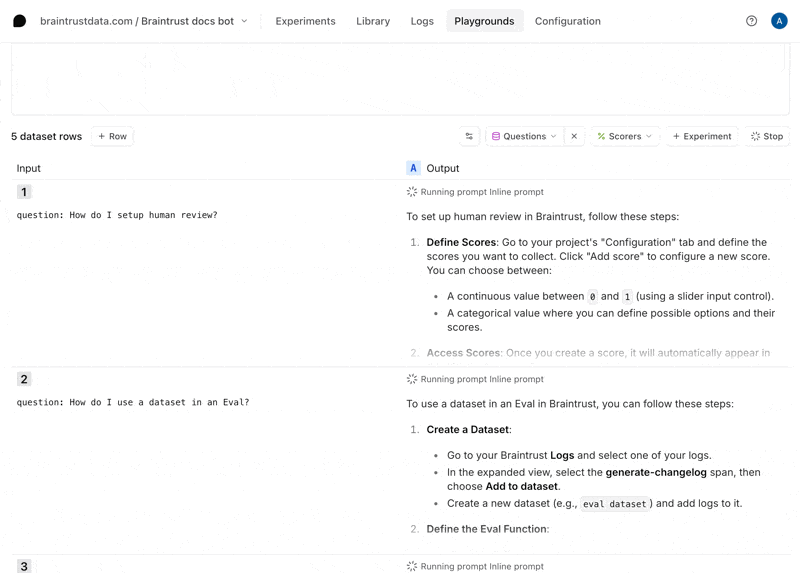
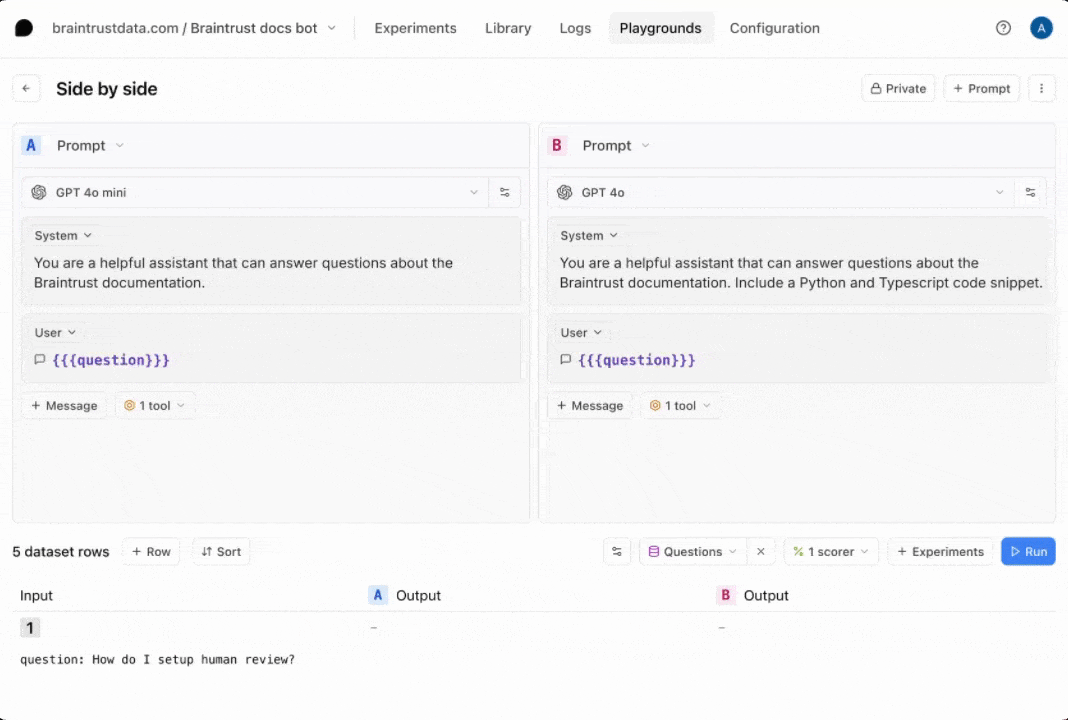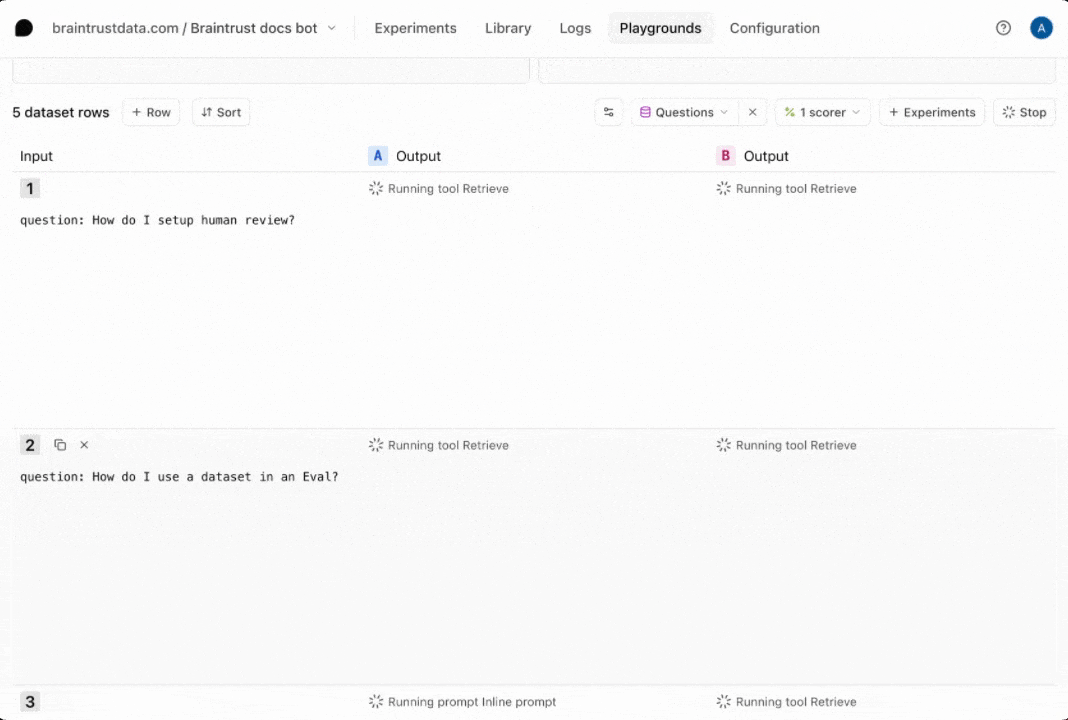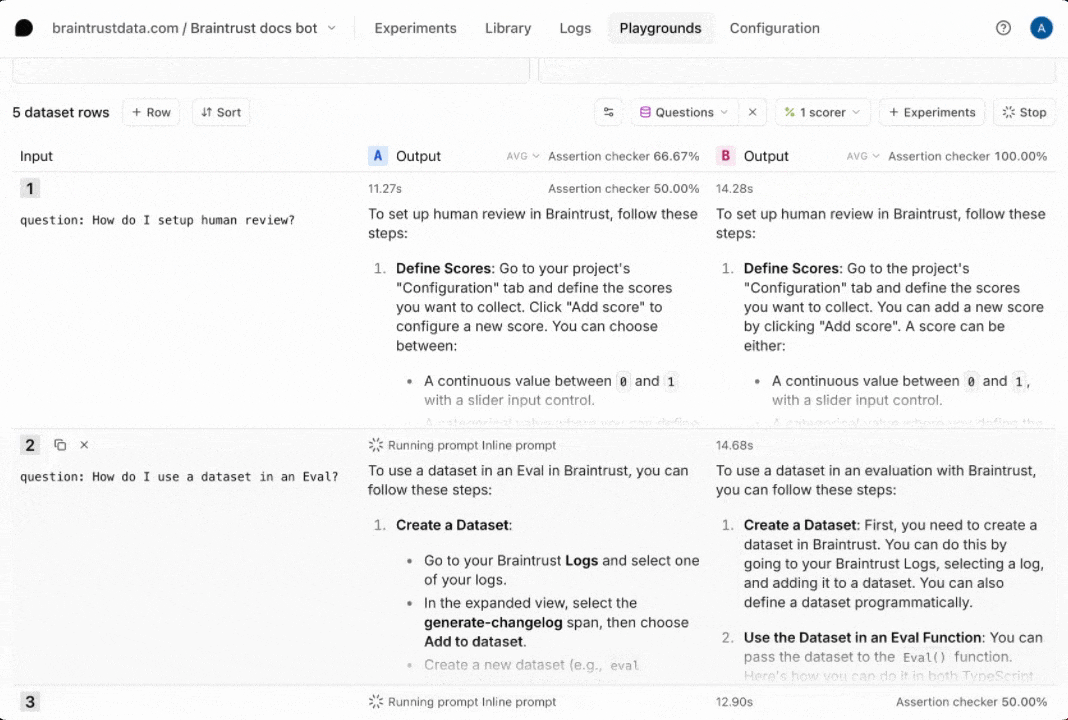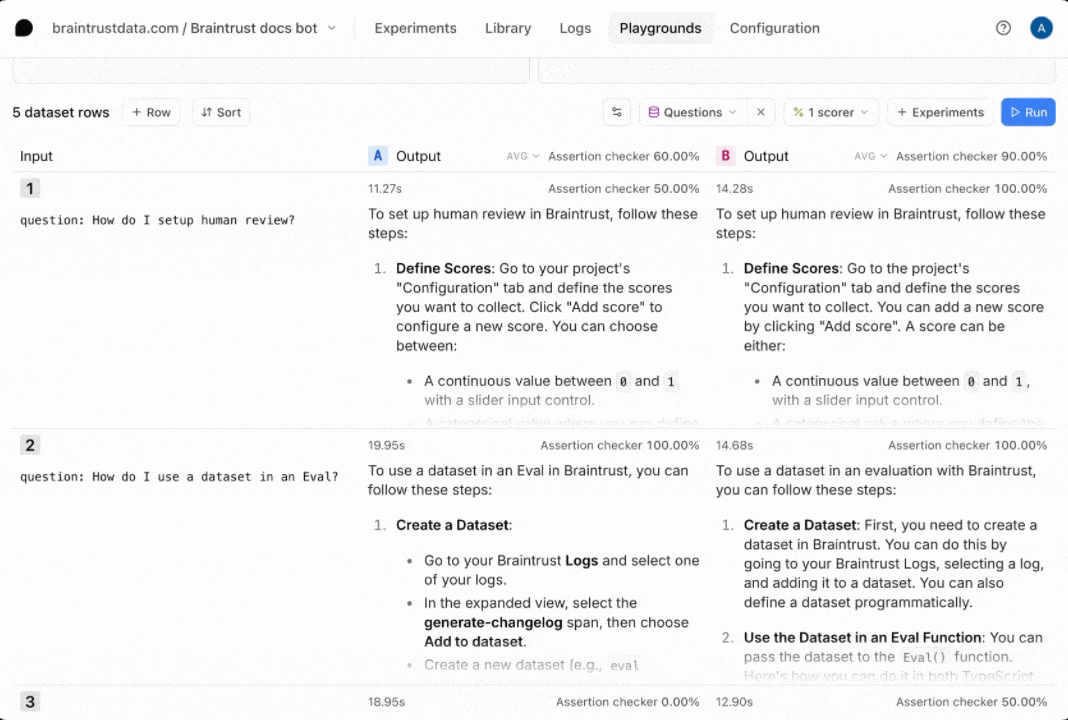
Define a scorer
Now that we have an interactive environment to test out our prompt and tool call, let’s define a scorer that helps us evaluate the results. Select the Scorers dropdown menu, then Create custom scorer. Choose the LLM-as-a-judge tab, and enter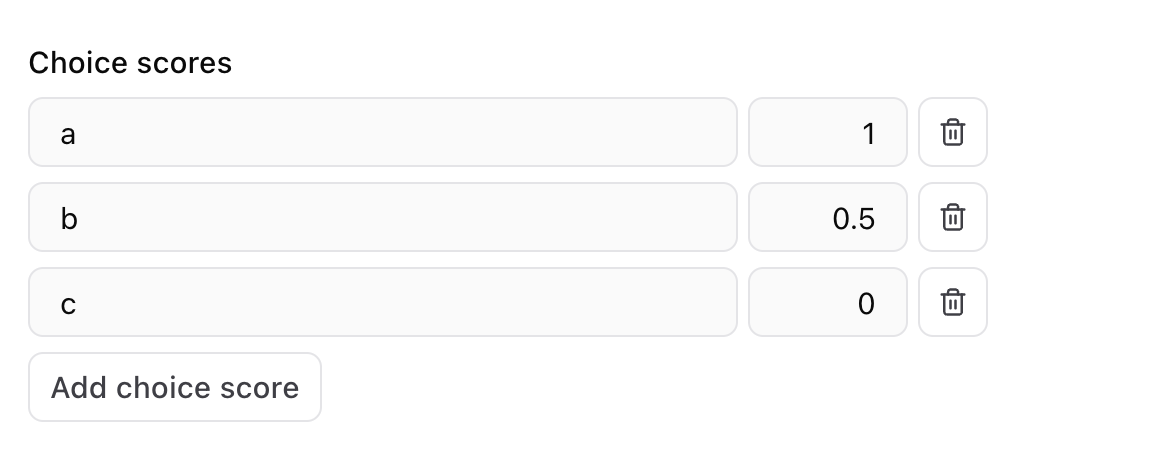

Tweak the prompt
Now, let’s tweak the prompt to see if we can improve the results. Hit the copy icon to duplicate your prompt and start tweaking. You can also tweak the original prompt and save your changes there if you’d like. For example, you can try instructing the model to always include a Python and TypeScript code snippet.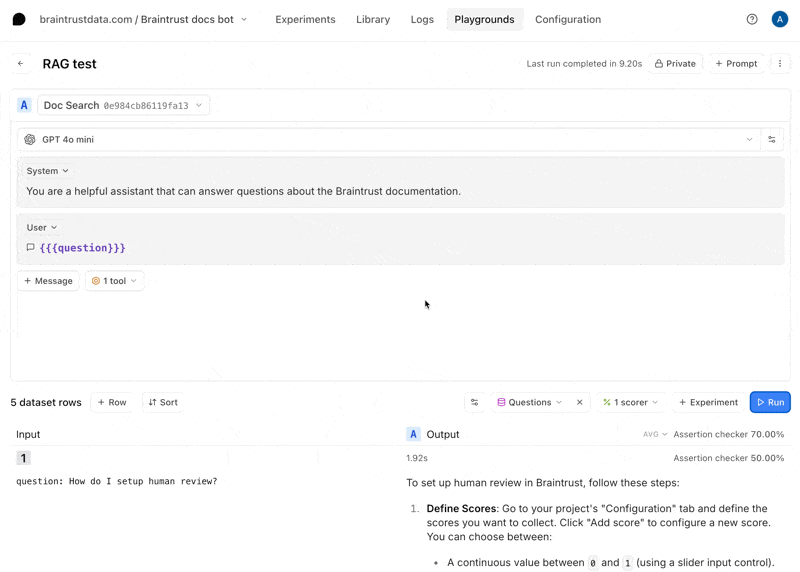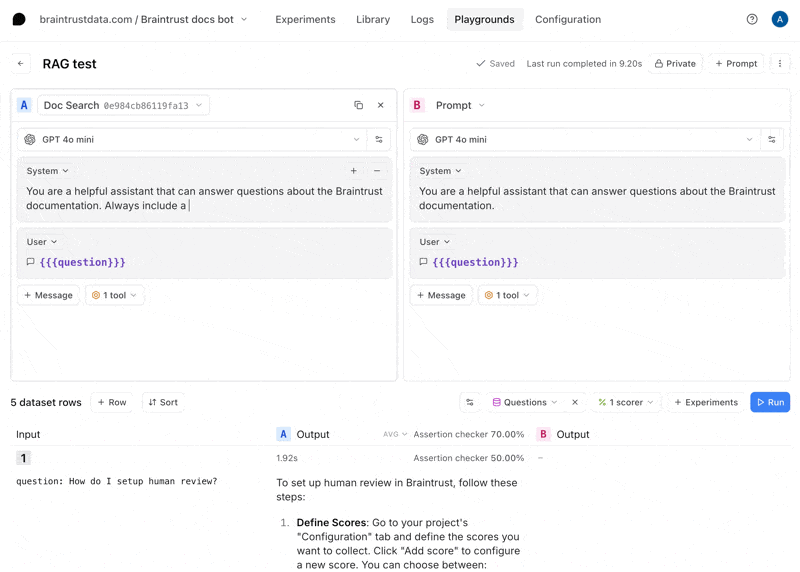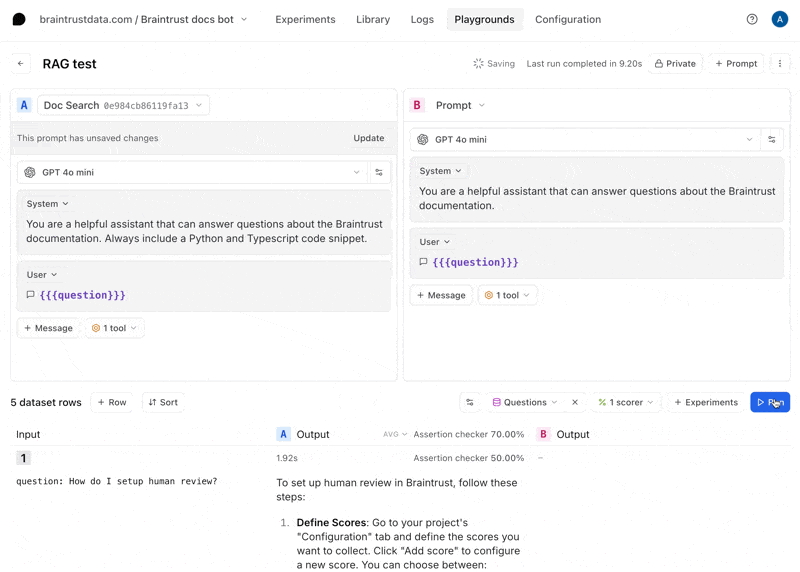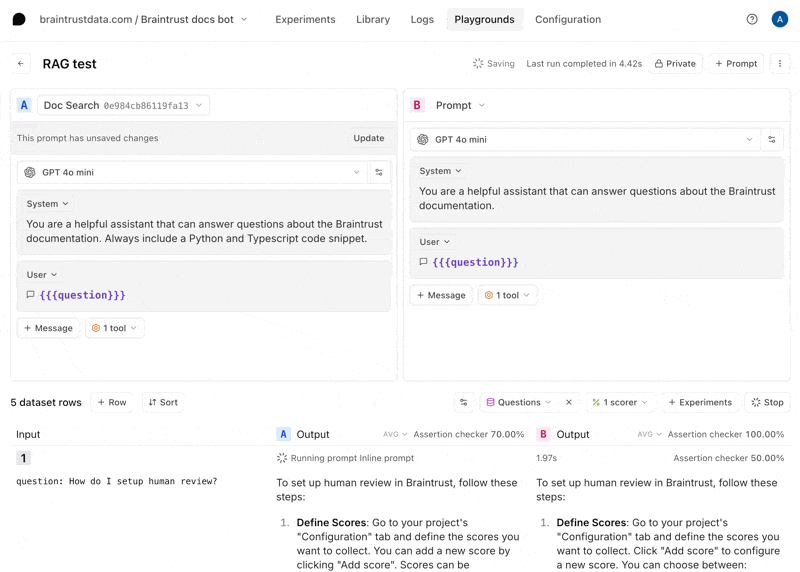
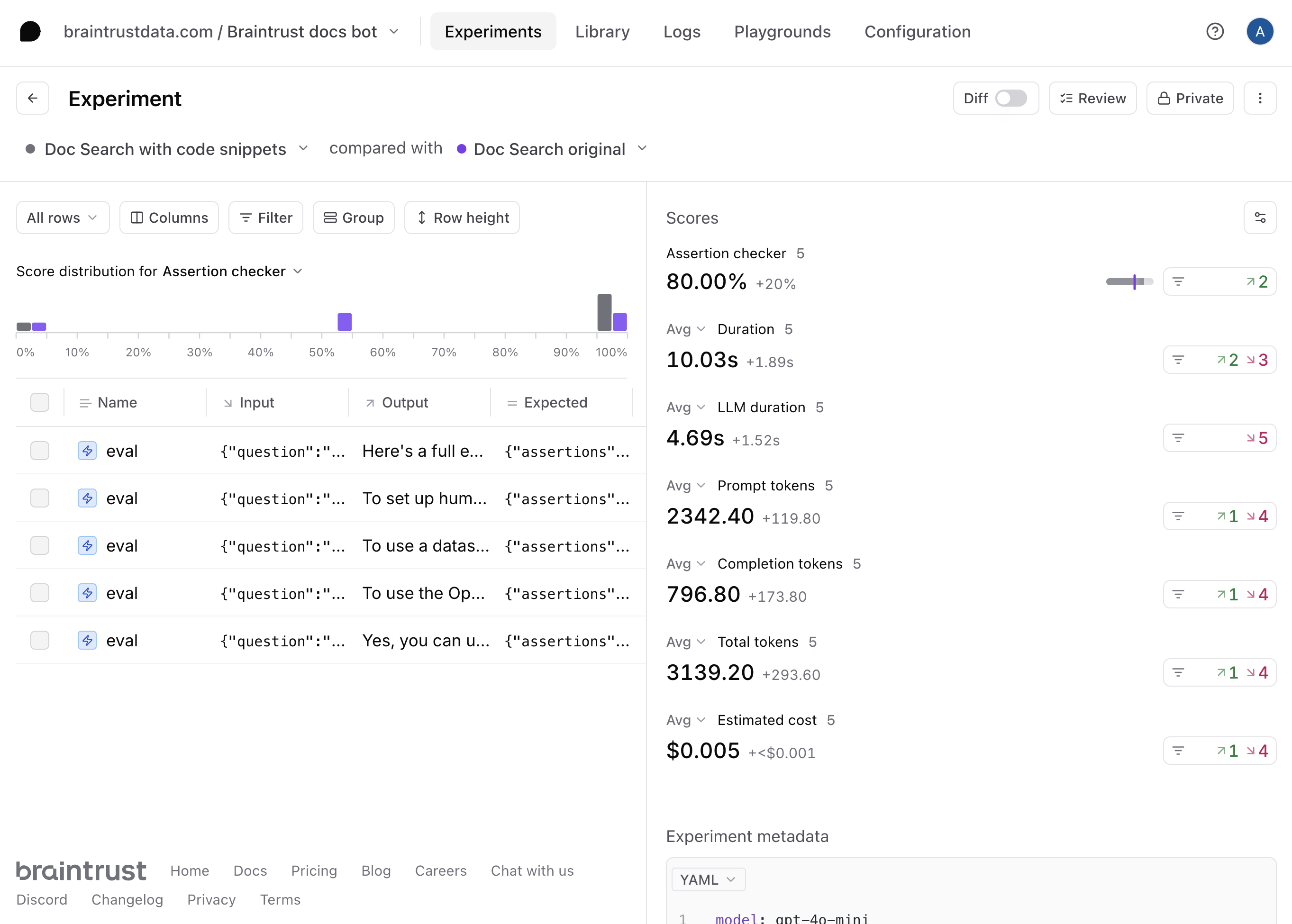
Run full experiments
The playground is very interactive, but if you’d like to create a more detailed evaluation, where you can:- See every step, including the tool calls and scoring prompts
- Compare side-by-side diffs, improvements, and regressions
- Share a permanent snapshot of results with others on your team
Next steps
Now that you’ve built a RAG app in Braintrust, you can:- Deploy the prompt in your app
- Conduct more detailed evaluations
- Learn about logging LLM calls to create a data flywheel